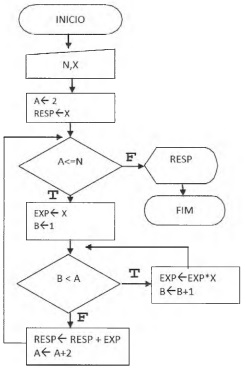
Considere as afirmações a seguir.
I. Se duas amostras aleatórias de tamanhos N
1 e N
2 são extraídas de populações normais cujos desvios são ?
1 = ?
2 e se ambas têm médias
X1 e
X2 e desvios S
1 e S
2, respectivamente, então para testar a hipótese H
0 de que as amostras proveem da mesma população, adota-se o escore t dado por:
t = (
X1 -
X2 )/?(1/N
1 + 1/N
2)
0,5, em que
? = [(N
1S
12 + N
2 s
22)/(N
1 + N
2 - 2)]
0,5II. Na distribuição de "Student", o número de graus de liberdade é igual a N
1 + N
2 - 2.
III.Na distribuição de qui-quadrado o valor máximo ocorre para
X2 = v - 2, para v ? 2.
IV.
O número de graus de liberdade de uma estatística, v, é definido como o número N de observações independentes da amostra menos o número k dos parâmetros populacionais que devem ser estimados por meio de observações amostrais.
V. Suponha um conjunto de N elementos, dos quais k apresenta uma certa característica. Se forem extraídos n elementos sem reposição do conjunto, temos uma distribuição hipergeométrica com probabilidade P[ X = x ]
dada por
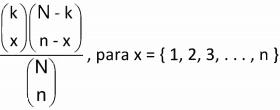
Dentre as afirmações feitas, quantas são falsas?
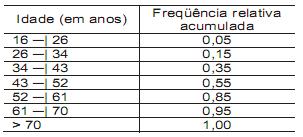
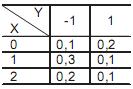

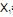 = face do dado 1,
= face do dado 1,  = face do dado 2 e os eventos:
= face do dado 2 e os eventos: